Histogram#
hist provides two types of histograms, in which Hist is the general class, NamedHist is a forced-name class. hist supports the whole workflow for a histogram’s lifecycle, including some plotting tools and shortcuts which are pretty useful for HEP studies. Here, you can see how to serialize/deserialize (will be achieved), construct, use, and visualize histograms.

Hist#
Hist is the general class in the hist package based on boost-histogram’s Histogram. Here is how to serialize/deserialize (will be achieved), construct, use, and visualize histograms via Hist.
Initialize Hist#
You need to initialized Hist first before you use it. Two ways are provided: you can just fill the axes into the Hist instance and create it; you can also add axes in Hist object via hist proxy.
When initializing you don’t have to use named-axes, axes without names are allowed. Using named-axes is recommended, because you will get more shortcuts to make the best of hist (there is also a classed called NamedHist which forces names be used most places). Duplicated non-empty names are not allowed in the Hist as name is the unique identifier for a Hist object.
[1]:
import hist
from hist import Hist
Standard method:#
[2]:
# fill the axes
h = Hist(
hist.axis.Regular(
50, -5, 5, name="S", label="s [units]", underflow=False, overflow=False
),
hist.axis.Regular(
50, -5, 5, name="W", label="w [units]", underflow=False, overflow=False
),
)
Shortcut method:#
One benefit of the shortcut method is that you can work entirely from Hist, so from hist import Hist can be used.
[3]:
# add the axes, finalize with storage
h = (
Hist.new.Reg(50, -5, 5, name="S", label="s [units]", flow=False)
.Reg(50, -5, 5, name="W", label="w [units]", flow=False)
.Double()
)
Manipulate Hist#
Fill Hist#
After initializing the Hist, the most likely thing you want to do is to fill it. The normal method to fill the histogram is just to pass the data to .fill(), and the data will be filled in the index order. If you have axes all with names in your Hist, you will have another option – filling by names in the order of names given.
[4]:
import numpy as np
s_data = np.random.normal(size=50_000)
w_data = np.random.normal(size=50_000)
# normal fill
h.fill(s_data, w_data)
# Clear the data since we want to fill again with the same data
h.reset()
# fill by names
h.fill(W=w_data, S=s_data)
[4]:
Regular(50, -5, 5, underflow=False, overflow=False, name='W', label='w [units]')
Double() Σ=50000.0
Access Bins#
hist allows you to access the bins of your Hist by various ways. Besides the normal access by index, you can use locations (supported by boost-histogram), complex numbers, and the dictionary to access the bins.
[5]:
# Access by bin number
h[25, 25]
[5]:
294.0
[6]:
# Access by data coordinate
# Identical to: h[hist.loc(0), hist.loc(0)]
h[0j, 0j]
[6]:
294.0
[7]:
# Identical to: h[hist.loc(-1) + 5, hist.loc(-4) + 20]
h[-1j + 5, -4j + 20]
[7]:
294.0
If you are accessing multiple bins, you can use complex numbers to rebin.
[8]:
# Identical to: h.project("S")[20 : 30 : hist.rebin(2)]
h.project("S")[20:30:2j]
[8]:
Double() Σ=34100.0
Dictionary is allowed when accessing bins. If you have axes all with names in your Hist, you can also access them according to the axes’ names.
[9]:
s = Hist(
hist.axis.Regular(50, -5, 5, name="Norm", label="normal distribution"),
hist.axis.Regular(50, 0, 1, name="Unif", label="uniform distribution"),
hist.axis.StrCategory(["hi", "hello"], name="Greet"),
hist.axis.Boolean(name="Yes"),
hist.axis.Integer(0, 1000, name="Int"),
)
[10]:
s.fill(
Norm=np.random.normal(size=1000),
Unif=np.random.uniform(size=1000),
Greet=["hi"] * 800 + ["hello"] * 200,
Yes=[True] * 600 + [False] * 400,
Int=np.ones(1000, dtype=int),
)
[10]:
Hist(
Regular(50, -5, 5, name='Norm', label='normal distribution'),
Regular(50, 0, 1, name='Unif', label='uniform distribution'),
StrCategory(['hi', 'hello'], name='Greet'),
Boolean(name='Yes'),
Integer(0, 1000, name='Int'),
storage=Double()) # Sum: 1000.0
[11]:
s[0j, -0j + 2, "hi", True, 1]
[11]:
1.0
[12]:
s[{0: 0j, 3: True, 4: 1, 1: -0j + 2, 2: "hi"}] += 10
s[{"Greet": "hi", "Unif": -0j + 2, "Yes": True, "Int": 1, "Norm": 0j}]
[12]:
11.0
Get Density#
If you want to get the density of an existing histogram, .density() is capable to do it and will return you the density array without overflow and underflow bins. (This may return a “smart” object in the future; for now it’s a simple NumPy array.)
[13]:
h[25:30, 25:30].density()
[13]:
array([[1.27670662, 1.47646344, 1.06826472, 1.04655202, 0.85113775],
[1.33750217, 1.07260726, 1.16814313, 1.00312663, 0.82942505],
[1.16814313, 1.15511551, 1.12906027, 0.94233108, 0.95535869],
[1.13774535, 1.0986625 , 0.97707139, 0.82942505, 0.62532569],
[0.88153552, 0.83376759, 0.75994442, 0.74257426, 0.63401077]])
Get Project#
Hist allows you to get the projection of an N-D Histogram:
[14]:
s_2d = s.project("Norm", "Unif")
s_2d
[14]:
Regular(50, 0, 1, name='Unif', label='uniform distribution')
Double() Σ=1010.0
Get Profile#
To compute the (N-1)-D profile from an existing histogram, you can:
[15]:
xy = np.array(
[
[-2, 1.5],
[-2, -3.5],
[-2, 1.5], # x = -2
[0.0, -2.0],
[0.0, -2.0],
[0.0, 0.0],
[0.0, 2.0],
[0.0, 4.0], # x = 0
[2, 1.5], # x = +2
]
)
h_xy = hist.Hist(
hist.axis.Regular(5, -5, 5, name="x"), hist.axis.Regular(5, -5, 5, name="y")
).fill(*xy.T)
# Profile out the y-axis
hp = h_xy.profile("y")
hp.values()[1:-1]
# hp.variances()[1:-1]
[15]:
array([-1.48029737e-16, 4.00000000e-01, 2.00000000e+00])
Plot Hist#
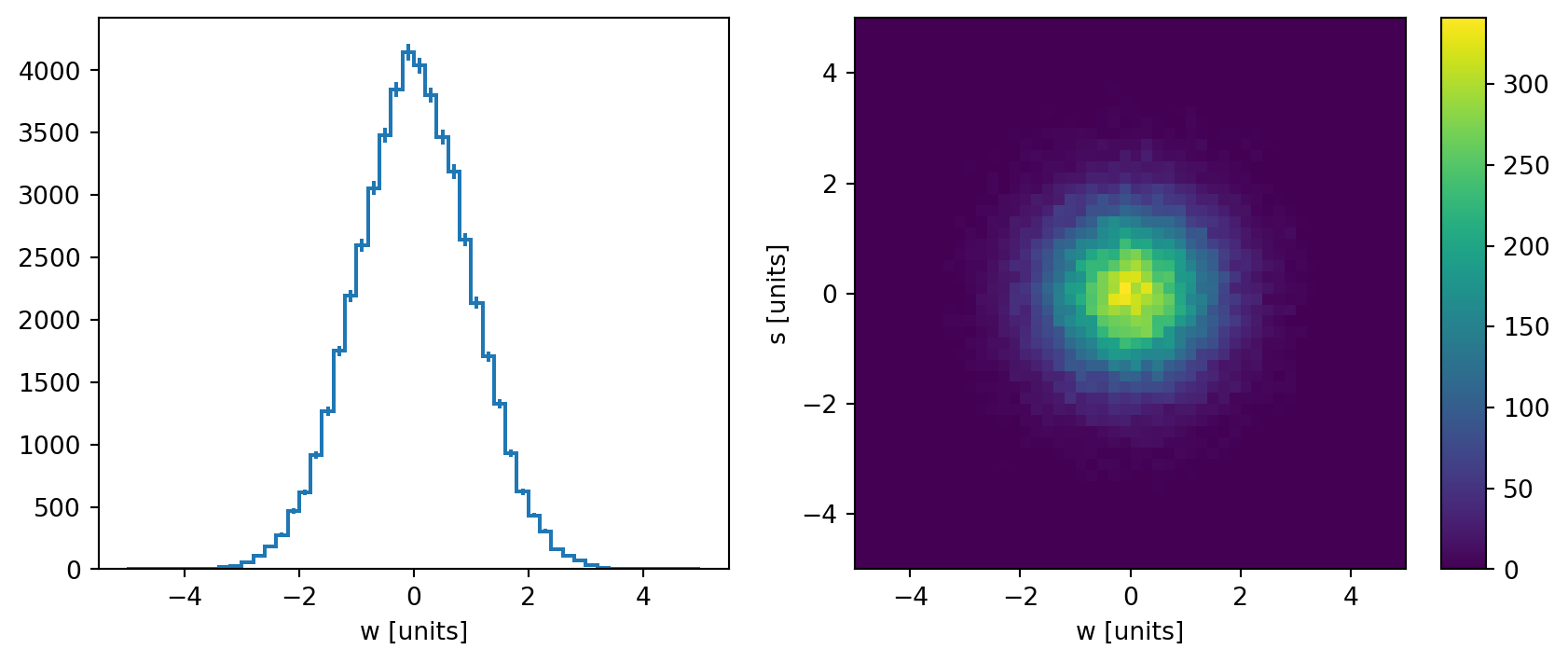
One of the most amazing feature of hist is it’s powerful plotting family. Here is a brief demonstration of how to plot Hist. You can get more information in the section of Plots.
[16]:
import matplotlib.pyplot as plt
# auto-plot
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
h.project("W").plot(ax=axs[0])
h.project("W", "S").plot(ax=axs[1])
plt.show()
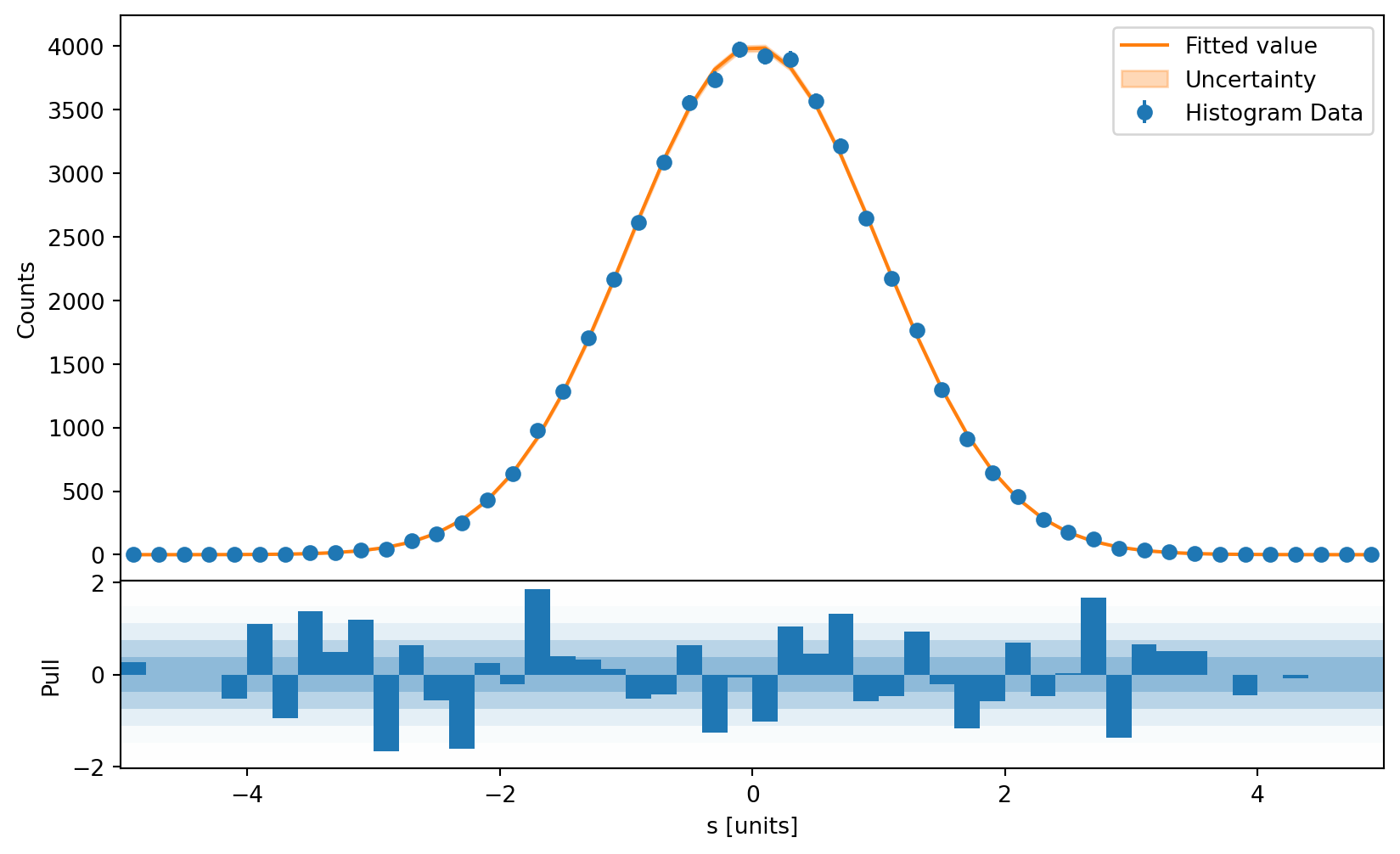
This is an example of a pull plot:
[17]:
from uncertainties import unumpy as unp
def pdf(x, a=1 / np.sqrt(2 * np.pi), x0=0, sigma=1, offset=0):
exp = unp.exp if a.dtype == np.dtype("O") else np.exp
return a * exp(-((x - x0) ** 2) / (2 * sigma**2)) + offset
(The uncertainty is non-significant as we filled a great quantities of observation points above.)
[18]:
plt.figure(figsize=(10, 6))
h.project("S").plot_pull(pdf)
plt.show()
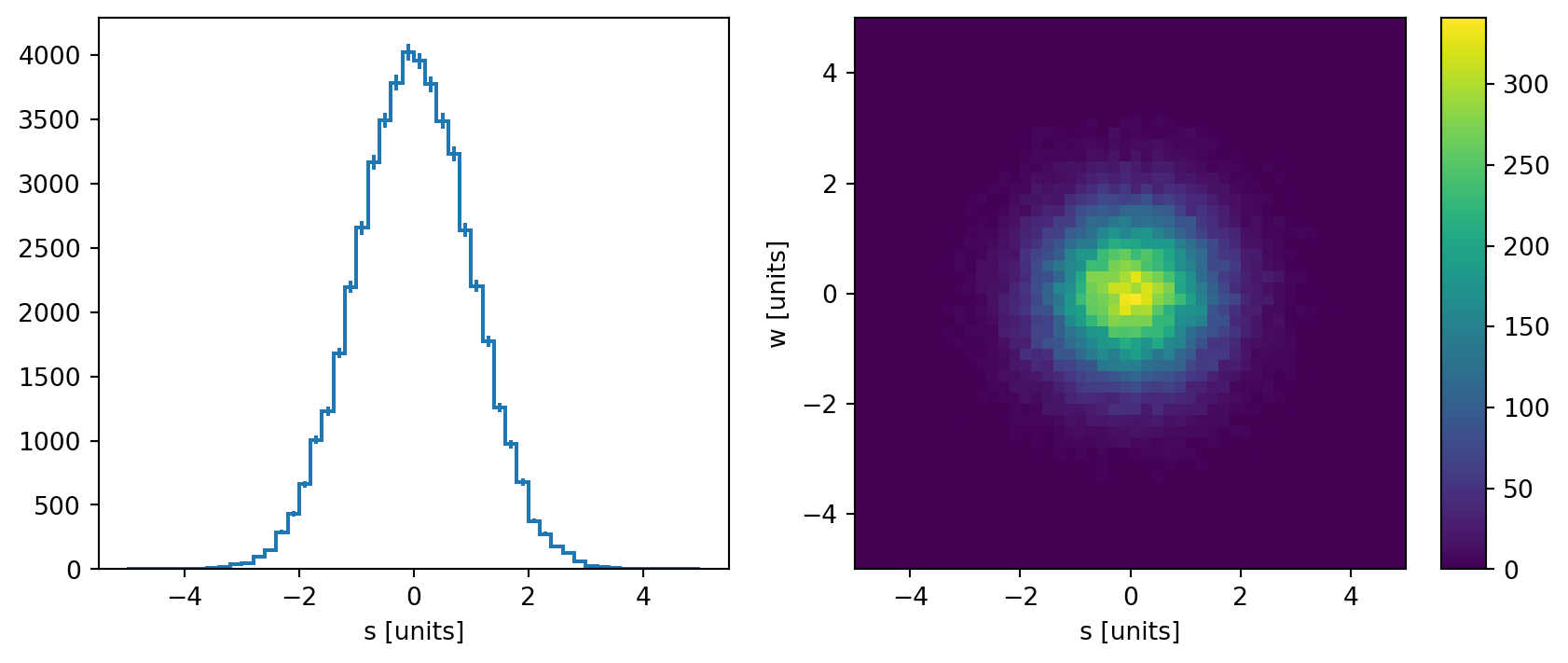
You can also pass Hist objects directly to mplhep (which is what is used for the backend of Hist anyway):
[19]:
import mplhep
# auto-plot
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
mplhep.histplot(h.project("S"), ax=axs[0])
mplhep.hist2dplot(h, ax=axs[1])
plt.show()
NamedHist#
If you want to force names always be used, you can use NamedHist. This reduces functionality but can reduce mistaking one axes for another.
[20]:
h = hist.NamedHist(
hist.axis.Regular(
50, -5, 5, name="S", label="s [units]", underflow=False, overflow=False
),
hist.axis.Regular(
50, -5, 5, name="W", label="w [units]", underflow=False, overflow=False
),
)
[21]:
# should all use names
s_data = np.random.normal(size=50_000)
w_data = np.random.normal(size=50_000)
h.fill(W=w_data, S=s_data)
assert h[25, 25] == h[0j, 1j - 5] == h[{"W": 25, "S": 0j}]
assert h[:, 0:50:5j].project("S")
[22]:
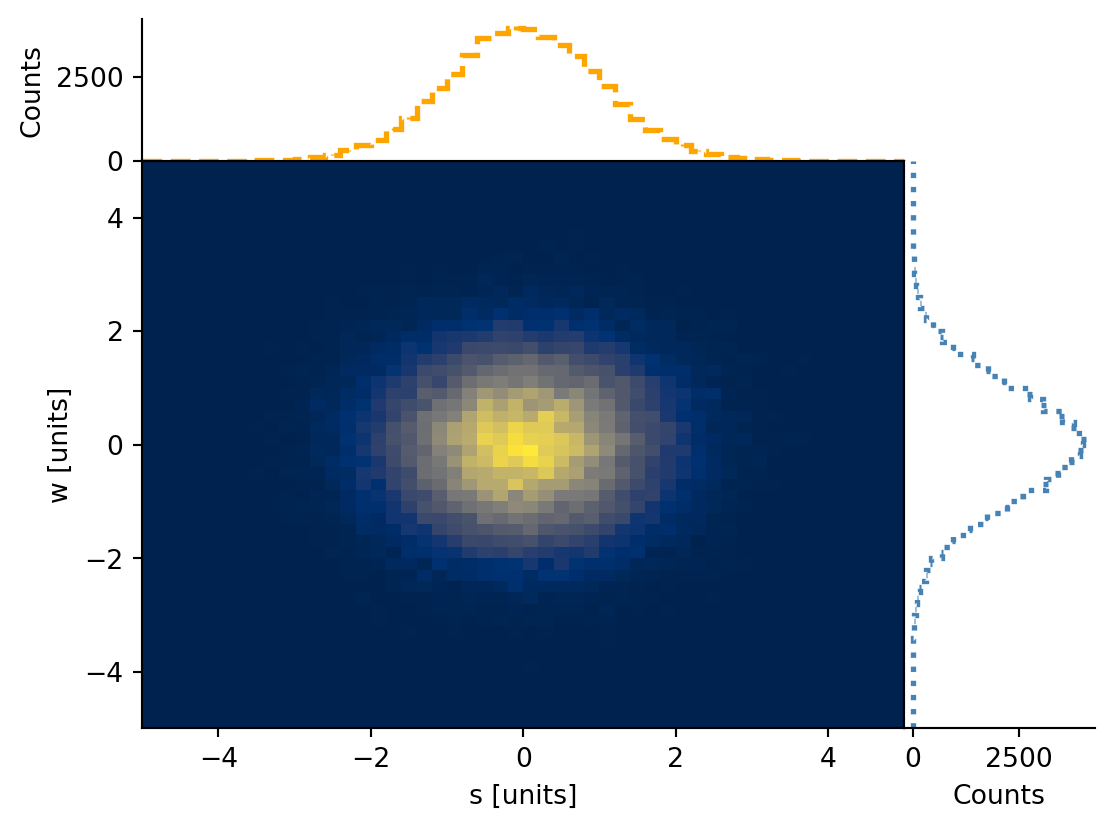
# plot2d full
h.plot2d_full(
main_cmap="cividis",
top_ls="--",
top_color="orange",
top_lw=2,
side_ls=":",
side_lw=2,
side_color="steelblue",
)
plt.show()
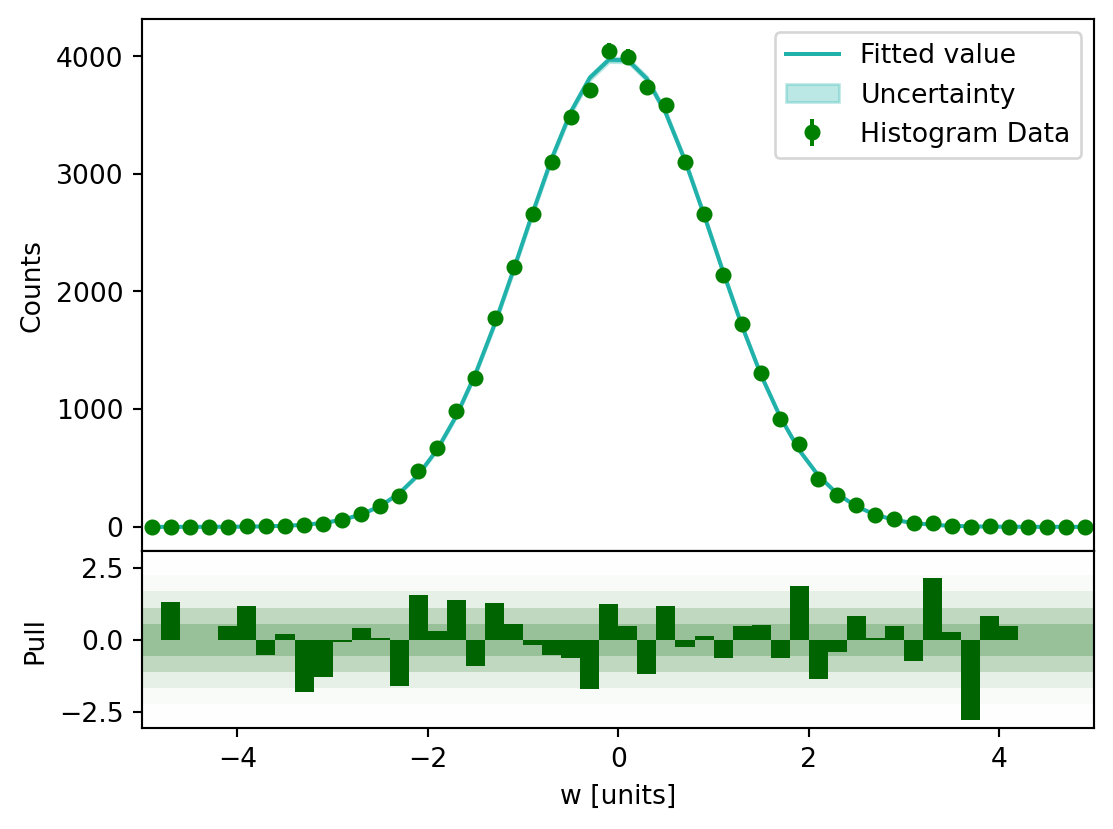
[23]:
# plot pull
h.project("W").plot_pull(
pdf,
eb_ecolor="green",
eb_mfc="green",
eb_mec="green",
eb_fmt="o",
eb_ms=5,
fp_color="lightseagreen",
pp_color="darkgreen",
pp_alpha=0.4,
pp_ec=None,
bar_color="darkgreen",
)
plt.show()
hist.dask#
If you want to fill your histograms using delayed arrays provided by dask start by importing the hist.dask sub-package, usually calling it dah. Within this sub-package dask versions of Hist and NamedHist are available. All methods of Hist and NamedHist instantiation discussed above are supported in their dask forms. This method of using hist can be best used when operating on large datasets and distributed clusters.
An important note: as with all dask collections the in-memory and finalized form of the histogram is only rendered when you call .compute() or dask.compute() on the dask collection! Until that point you are manipulating a task graph that represents the process of filling and creating that histogram.
[24]:
import dask.array as da
import hist.dask as dah
Hist#
Below we’ll use a dask array to fill a hist.dask.Hist lazily, as a proxy for filling it on a cluster, and then plot the resulting histogram!
[25]:
# add the axes, finalize with storage
h = (
dah.Hist.new.Reg(50, -5, 5, name="S", label="s [units]", flow=False)
.Reg(50, -5, 5, name="W", label="w [units]", flow=False)
.Double()
)
s_data = da.random.standard_normal(size=(50_000,), chunks=(1000,))
w_data = da.random.standard_normal(size=(50_000,), chunks=(1000,))
# delayed fill
h.fill(W=w_data, S=s_data)
import matplotlib.pyplot as plt
# auto-plot
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
h.project("W").plot(ax=axs[0])
h.project("W", "S").plot(ax=axs[1])
plt.show()
# h.visualize() # Uncomment this to see that only the task graph is created and there is no filled histogram!
[26]:
# render in-memory histogram
h = h.compute()
import matplotlib.pyplot as plt
# auto-plot
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
h.project("W").plot(ax=axs[0])
h.project("W", "S").plot(ax=axs[1])
plt.show()

NamedHist#
Below we’ll use a dask array to fill a hist.dask.NamedHist lazily, as a proxy for filling it on a cluster, and then plot the resulting histogram!
[27]:
h = dah.NamedHist(
hist.axis.Regular(
50, -5, 5, name="S", label="s [units]", underflow=False, overflow=False
),
hist.axis.Regular(
50, -5, 5, name="W", label="w [units]", underflow=False, overflow=False
),
)
# should all use names
s_data = da.random.standard_normal(size=(50_000,), chunks=(1000,))
w_data = da.random.standard_normal(size=(50_000,), chunks=(1000,))
h.fill(W=w_data, S=s_data)
h = h.compute()
assert h[25, 25] == h[0j, 1j - 5] == h[{"W": 25, "S": 0j}]
assert h[:, 0:50:5j].project("S")
# plot2d full
h.plot2d_full(
main_cmap="cividis",
top_ls="--",
top_color="orange",
top_lw=2,
side_ls=":",
side_lw=2,
side_color="steelblue",
)
plt.show()
